|
|
||
|---|---|---|
| .gitattributes | ||
| README.md | ||
| config.json | ||
| janus_pro_teaser1.png | ||
| janus_pro_teaser2.png | ||
| preprocessor_config.json | ||
| processor_config.json | ||
| pytorch_model-00001-of-00002.bin | ||
| pytorch_model-00002-of-00002.bin | ||
| pytorch_model.bin.index.json | ||
| special_tokens_map.json | ||
| tokenizer.json | ||
| tokenizer_config.json | ||
{kind=link}
{kind=link}
README.md
| license | license_name | license_link | pipeline_tag | library_name | tags | |||
|---|---|---|---|---|---|---|---|---|
| mit | deepseek | LICENSE | any-to-any | transformers |
|
1. Introduction
Janus-Pro is a novel autoregressive framework that unifies multimodal understanding and generation. It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility. Janus-Pro surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus-Pro make it a strong candidate for next-generation unified multimodal models.
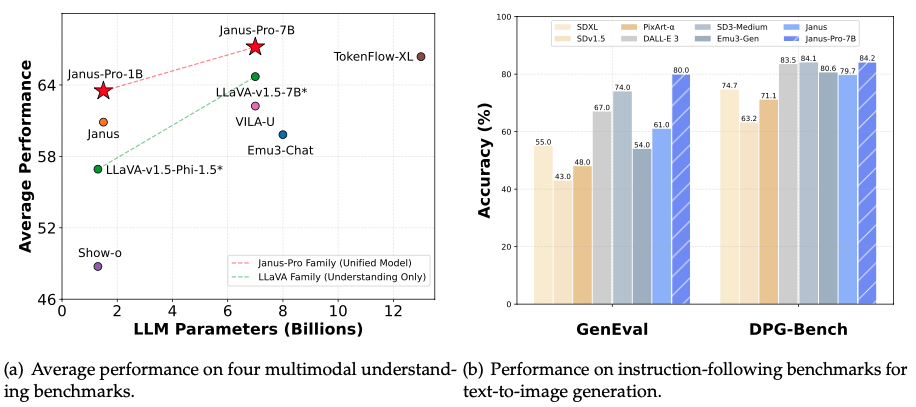

2. Model Summary
Janus-Pro is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation. Janus-Pro is constructed based on the DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base.
For multimodal understanding, it uses the SigLIP-L as the vision encoder, which supports 384 x 384 image input. For image generation, Janus-Pro uses the tokenizer from here with a downsample rate of 16.
3. Quick Start
Please refer to Github Repository
4. License
This code repository is licensed under the MIT License. The use of Janus-Pro models is subject to DeepSeek Model License.
5. Citation
@article{chen2025janus,
title={Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling},
author={Chen, Xiaokang and Wu, Zhiyu and Liu, Xingchao and Pan, Zizheng and Liu, Wen and Xie, Zhenda and Yu, Xingkai and Ruan, Chong},
journal={arXiv preprint arXiv:2501.17811},
year={2025}
}
6. Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.