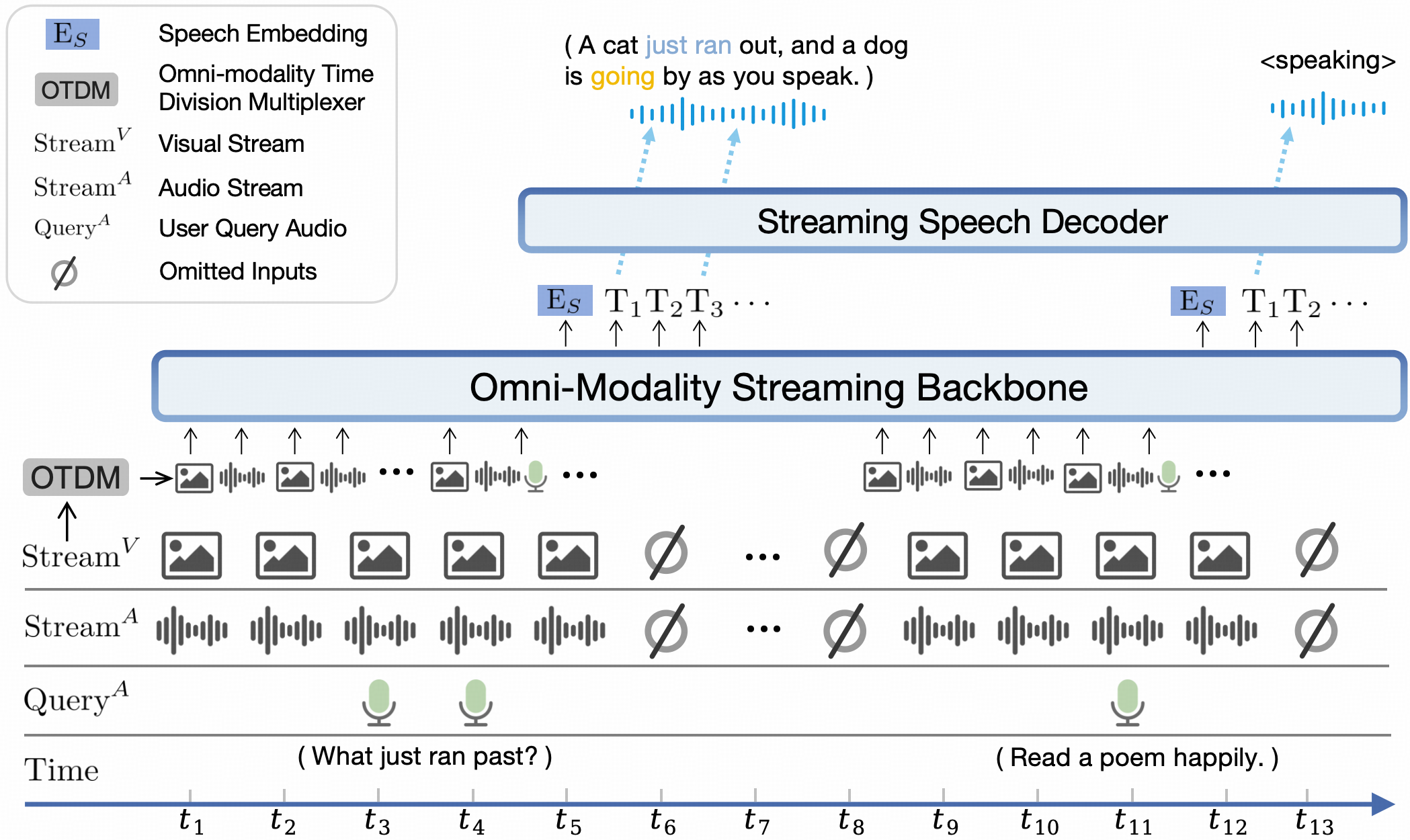
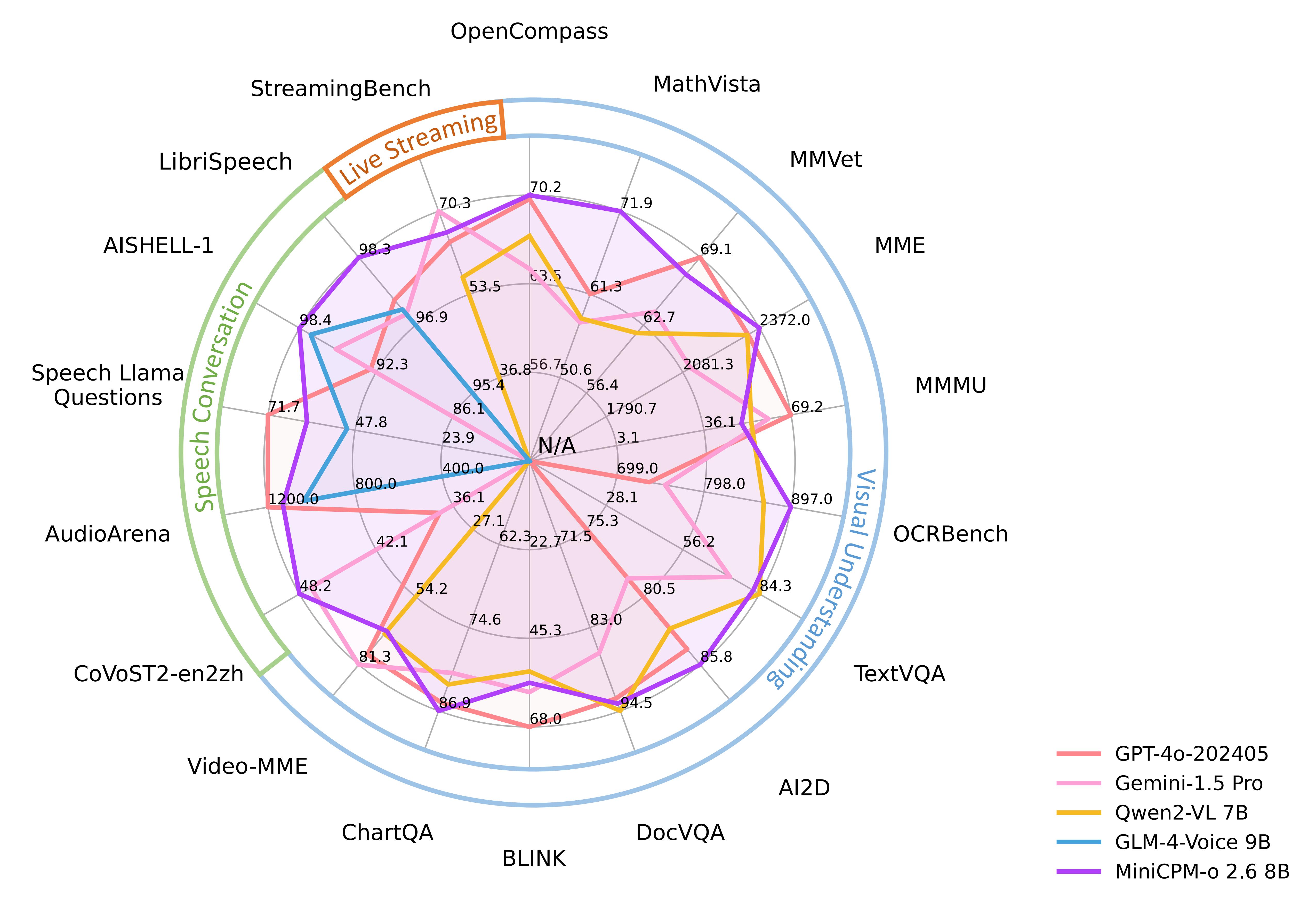
| Model | Size | Token Density+ | OpenCompass | OCRBench | MathVista mini | ChartQA | MMVet | MMStar | MME | MMB1.1 test | AI2D | MMMU val | HallusionBench | TextVQA val | DocVQA test | MathVerse mini | MathVision | MMHal Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||||||||||||
| GPT-4o-20240513 | - | 1088 | 69.9 | 736 | 61.3 | 85.7 | 69.1 | 63.9 | 2328.7 | 82.2 | 84.6 | 69.2 | 55.0 | - | 92.8 | 50.2 | 30.4 | 3.6 |
| Claude3.5-Sonnet | - | 750 | 67.9 | 788 | 61.6 | 90.8 | 66.0 | 62.2 | 1920.0 | 78.5 | 80.2 | 65.9 | 49.9 | - | 95.2 | - | - | 3.4 |
| Gemini-1.5-Pro | - | - | 64.4 | 754 | 57.7 | 81.3 | 64.0 | 59.1 | 2110.6 | 73.9 | 79.1 | 60.6 | 45.6 | 73.5 | 86.5 | - | 19.2 | - |
| GPT-4o-mini-20240718 | - | 1088 | 64.1 | 785 | 52.4 | - | 66.9 | 54.8 | 2003.4 | 76.0 | 77.8 | 60.0 | 46.1 | - | - | - | - | 3.3 |
| Open Source | ||||||||||||||||||
| Cambrian-34B | 34B | 1820 | 58.3 | 591 | 50.3 | 75.6 | 53.2 | 54.2 | 2049.9 | 77.8 | 79.5 | 50.4 | 41.6 | 76.7 | 75.5 | - | - | - |
| GLM-4V-9B | 13B | 784 | 59.1 | 776 | 51.1 | - | 58.0 | 54.8 | 2018.8 | 67.9 | 71.2 | 46.9 | 45.0 | - | - | - | - | - |
| Pixtral-12B | 12B | 256 | 61.0 | 685 | 56.9 | 81.8 | 58.5 | 54.5 | - | 72.7 | 79.0 | 51.1 | 47.0 | 75.7 | 90.7 | - | - | - |
| DeepSeek-VL2-27B (4B) | 27B | 672 | 66.4 | 809 | 63.9 | 86.0 | 60.0 | 61.9 | 2253.0 | 81.2 | 83.8 | 54.0 | 45.3 | 84.2 | 93.3 | - | - | 3.0 |
| Qwen2-VL-7B | 8B | 784 | 67.1 | 866 | 58.2 | 83.0 | 62.0 | 60.7 | 2326.0 | 81.8 | 83.0 | 54.1 | 50.6 | 84.3 | 94.5 | 31.9 | 16.3 | 3.2 |
| LLaVA-OneVision-72B | 72B | 182 | 68.1 | 741 | 67.5 | 83.7 | 60.6 | 65.8 | 2261.0 | 85.0 | 85.6 | 56.8 | 49.0 | 80.5 | 91.3 | 39.1 | - | 3.5 |
| InternVL-2.5-8B | 8B | 706 | 68.3 | 822 | 64.4 | 84.8 | 62.8 | 62.8 | 2344.0 | 83.6 | 84.5 | 56.0 | 50.1 | 79.1 | 93.0 | 39.5 | 19.7 | 3.4 |
| MiniCPM-V 2.6 | 8B | 2822 | 65.2 | 852* | 60.6 | 79.4 | 60.0 | 57.5 | 2348.4* | 78.0 | 82.1 | 49.8* | 48.1* | 80.1 | 90.8 | 25.7 | 18.3 | 3.6 |
| MiniCPM-o 2.6 | 8B | 2822 | 70.2 | 897* | 71.9* | 86.9* | 67.5 | 64.0 | 2372.0* | 80.5 | 85.8 | 50.4* | 51.9 | 82.0 | 93.5 | 41.4* | 23.1* | 3.8 |
| Model | Size | BLINK-val | Mantis-Eval | MIRB | Video-MME (wo / w subs) |
|---|---|---|---|---|---|
| Proprietary | |||||
| GPT-4o-20240513 | - | 68 | - | - | 71.9/77.2 |
| GPT4V | - | 54.6 | 62.7 | 53.1 | 59.9/63.3 |
| Open-source | |||||
| LLaVA-NeXT-Interleave 14B | 14B | 52.6 | 66.4 | 30.2 | - |
| LLaVA-One-Vision-72B | 72B | 55.4 | 77.6 | - | 66.2/69.5 |
| MANTIS 8B | 8B | 49.1 | 59.5 | 34.8 | - |
| Qwen2-VL-7B | 8B | 53.2 | 69.6* | 67.6* | 63.3/69.0 |
| InternVL-2.5-8B | 8B | 54.8 | 67.7 | 52.5 | 64.2/66.9 |
| MiniCPM-V 2.6 | 8B | 53 | 69.1 | 53.8 | 60.9/63.6 |
| MiniCPM-o 2.6 | 8B | 56.7 | 71.9 | 58.6 | 63.9/67.9 |
| Task | Size | ASR (zh) | ASR (en) | ASR | Emotion | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | CER↓ | WER↓ | BLEU↑ | ACC↑ | ||||||
| Dataset | AISHELL-1 | Fleurs zh | WenetSpeech test-net | LibriSpeech test-clean | GigaSpeech | TED-LIUM | CoVoST en2zh | CoVoST zh2en | MELD emotion | |
| Proprietary | ||||||||||
| GPT-4o-Realtime | - | 7.3* | 5.4* | 28.9* | 2.6* | 12.9* | 4.8* | 37.1* | 15.7* | 33.2* |
| Gemini-1.5-Pro | - | 4.5* | 5.9* | 14.3* | 2.9* | 10.6* | 3.0* | 47.3* | 22.6* | 48.4* |
| Open-Source | ||||||||||
| Qwen2-Audio | 8B | - | 7.5 | - | 1.6 | - | - | 45.2 | 24.4 | 55.3 |
| Qwen2-Audio-Instruction | 8B | 2.6* | 6.9* | 10.3* | 3.1* | 9.7* | 5.9* | 39.5* | 22.9* | 17.4* |
| GLM-4-Voice-Base | 9B | 2.5 | - | - | 2.8 | - | - | - | - | |
| MiniCPM-o 2.6 | 8B | 1.6 | 4.4 | 6.9 | 1.7 | 8.7 | 3.0 | 48.2 | 27.2 | 52.4 |
| Task | Size | SpeechQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | ACC↑ | G-Eval (10 point)↑ | Semantic ELO score↑ | Acoustic ELO score↑ | Overall ELO score↑ | UTMOS↑ | ASR-WER↓ | |||
| Dataset | Speech Llama Q. | Speech Web Q. | Speech Trivia QA | Speech AlpacaEval | AudioArena | |||||
| Proprietary | ||||||||||
| GPT-4o-Realtime | 71.7 | 51.6 | 69.7 | 7.4 | 1157 | 1203 | 1200 | 4.2 | 2.3 | |
| Open-Source | ||||||||||
| GLM-4-Voice | 9B | 50.0 | 32.0 | 36.4 | 5.1 | 999 | 1147 | 1035 | 4.1 | 11.7 |
| Llama-Omni | 8B | 45.3 | 22.9 | 10.7 | 3.9 | 960 | 878 | 897 | 3.2 | 24.3 |
| Moshi | 7B | 43.7 | 23.8 | 16.7 | 2.4 | 871 | 808 | 875 | 2.8 | 8.2 |
| Mini-Omni | 1B | 22.0 | 12.8 | 6.9 | 2.5 | 926 | 803 | 865 | 3.4 | 10.0 |
| MiniCPM-o 2.6 | 8B | 61.0 | 40.0 | 40.2 | 5.1 | 1088 | 1163 | 1131 | 4.2 | 9.8 |
| Task | TTS | |
|---|---|---|
| Metric | SIMO↑ | SIMO↑ |
| Dataset | Seed-TTS test-zh | Seed-TTS test-en |
| F5-TTS | 76 | 67 |
| CosyVoice | 75 | 64 |
| FireRedTTS | 63 | 46 |
| MiniCPM-o 2.6 | 57 | 47 |
| Model | Size | Real-Time Video Understanding | Omni-Source Understanding | Contextual Understanding | Overall | |||
|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||
| Gemini 1.5 Pro | - | 77.4 | 67.8 | 51.1 | 70.3 | |||
| GPT-4o | - | 74.5 | 51.0 | 48.0 | 64.1 | |||
| Claude-3.5-Sonnet | - | 74.0 | 41.4 | 37.8 | 59.7 | |||
| Open-source | ||||||||
| VILA-1.5 | 8B | 61.5 | 37.5 | 26.7 | 49.5 | |||
| LongVA | 7B | 63.1 | 35.9 | 30.2 | 50.7 | |||
| LLaVA-Next-Video-34B | 34B | 69.8 | 41.7 | 34.3 | 56.7 | |||
| Qwen2-VL-7B | 8B | 71.2 | 40.7 | 33.1 | 57.0 | |||
| InternVL2-8B | 8B | 70.1 | 42.7 | 34.1 | 57.0 | |||
| VITA-1.5 | 8B | 70.9 | 40.8 | 35.8 | 57.4 | |||
| LLaVA-OneVision-7B | 8B | 74.3 | 40.8 | 31.0 | 58.4 | |||
| InternLM-XC2.5-OL-7B | 8B | 75.4 | 46.2 | 33.6 | 60.8 | |||
| MiniCPM-V 2.6 | 8B | 72.4 | 40.2 | 33.4 | 57.7 | |||
| MiniCPM-o 2.6 | 8B | 79.9 | 53.4 | 38.5 | 66.0 | |||


