first commit
This commit is contained in:
parent
25698b1eac
commit
bad1c456c9
|
|
@ -0,0 +1,51 @@
|
||||||
|
Qwen LICENSE AGREEMENT
|
||||||
|
|
||||||
|
Qwen LICENSE AGREEMENT Release Date: September 19, 2024
|
||||||
|
|
||||||
|
By clicking to agree or by using or distributing any portion or element of the Qwen Materials, you will be deemed to have recognized and accepted the content of this Agreement, which is effective immediately.
|
||||||
|
|
||||||
|
1. Definitions
|
||||||
|
a. This Qwen LICENSE AGREEMENT (this "Agreement") shall mean the terms and conditions for use, reproduction, distribution and modification of the Materials as defined by this Agreement.
|
||||||
|
b. "We" (or "Us") shall mean Alibaba Cloud.
|
||||||
|
c. "You" (or "Your") shall mean a natural person or legal entity exercising the rights granted by this Agreement and/or using the Materials for any purpose and in any field of use.
|
||||||
|
d. "Third Parties" shall mean individuals or legal entities that are not under common control with us or you.
|
||||||
|
e. "Qwen" shall mean the large language models, and software and algorithms, consisting of trained model weights, parameters (including optimizer states), machine-learning model code, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by us.
|
||||||
|
f. "Materials" shall mean, collectively, Alibaba Cloud's proprietary Qwen and Documentation (and any portion thereof) made available under this Agreement.
|
||||||
|
g. "Source" form shall mean the preferred form for making modifications, including but not limited to model source code, documentation source, and configuration files.
|
||||||
|
h. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types.
|
||||||
|
|
||||||
|
2. Grant of Rights
|
||||||
|
You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Alibaba Cloud's intellectual property or other rights owned by us embodied in the Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Materials.
|
||||||
|
|
||||||
|
3. Redistribution
|
||||||
|
You may distribute copies or make the Materials, or derivative works thereof, available as part of a product or service that contains any of them, with or without modifications, and in Source or Object form, provided that you meet the following conditions:
|
||||||
|
a. You shall give any other recipients of the Materials or derivative works a copy of this Agreement;
|
||||||
|
b. You shall cause any modified files to carry prominent notices stating that you changed the files;
|
||||||
|
c. You shall retain in all copies of the Materials that you distribute the following attribution notices within a "Notice" text file distributed as a part of such copies: "Qwen is licensed under the Qwen LICENSE AGREEMENT, Copyright (c) Alibaba Cloud. All Rights Reserved."; and
|
||||||
|
d. You may add your own copyright statement to your modifications and may provide additional or different license terms and conditions for use, reproduction, or distribution of your modifications, or for any such derivative works as a whole, provided your use, reproduction, and distribution of the work otherwise complies with the terms and conditions of this Agreement.
|
||||||
|
|
||||||
|
4. Restrictions
|
||||||
|
If you are commercially using the Materials, and your product or service has more than 100 million monthly active users, you shall request a license from us. You cannot exercise your rights under this Agreement without our express authorization.
|
||||||
|
|
||||||
|
5. Rules of use
|
||||||
|
a. The Materials may be subject to export controls or restrictions in China, the United States or other countries or regions. You shall comply with applicable laws and regulations in your use of the Materials.
|
||||||
|
b. If you use the Materials or any outputs or results therefrom to create, train, fine-tune, or improve an AI model that is distributed or made available, you shall prominently display “Built with Qwen” or “Improved using Qwen” in the related product documentation.
|
||||||
|
|
||||||
|
6. Intellectual Property
|
||||||
|
a. We retain ownership of all intellectual property rights in and to the Materials and derivatives made by or for us. Conditioned upon compliance with the terms and conditions of this Agreement, with respect to any derivative works and modifications of the Materials that are made by you, you are and will be the owner of such derivative works and modifications.
|
||||||
|
b. No trademark license is granted to use the trade names, trademarks, service marks, or product names of us, except as required to fulfill notice requirements under this Agreement or as required for reasonable and customary use in describing and redistributing the Materials.
|
||||||
|
c. If you commence a lawsuit or other proceedings (including a cross-claim or counterclaim in a lawsuit) against us or any entity alleging that the Materials or any output therefrom, or any part of the foregoing, infringe any intellectual property or other right owned or licensable by you, then all licenses granted to you under this Agreement shall terminate as of the date such lawsuit or other proceeding is commenced or brought.
|
||||||
|
|
||||||
|
7. Disclaimer of Warranty and Limitation of Liability
|
||||||
|
a. We are not obligated to support, update, provide training for, or develop any further version of the Qwen Materials or to grant any license thereto.
|
||||||
|
b. THE MATERIALS ARE PROVIDED "AS IS" WITHOUT ANY EXPRESS OR IMPLIED WARRANTY OF ANY KIND INCLUDING WARRANTIES OF MERCHANTABILITY, NONINFRINGEMENT, OR FITNESS FOR A PARTICULAR PURPOSE. WE MAKE NO WARRANTY AND ASSUME NO RESPONSIBILITY FOR THE SAFETY OR STABILITY OF THE MATERIALS AND ANY OUTPUT THEREFROM.
|
||||||
|
c. IN NO EVENT SHALL WE BE LIABLE TO YOU FOR ANY DAMAGES, INCLUDING, BUT NOT LIMITED TO ANY DIRECT, OR INDIRECT, SPECIAL OR CONSEQUENTIAL DAMAGES ARISING FROM YOUR USE OR INABILITY TO USE THE MATERIALS OR ANY OUTPUT OF IT, NO MATTER HOW IT’S CAUSED.
|
||||||
|
d. You will defend, indemnify and hold harmless us from and against any claim by any third party arising out of or related to your use or distribution of the Materials.
|
||||||
|
|
||||||
|
8. Survival and Termination.
|
||||||
|
a. The term of this Agreement shall commence upon your acceptance of this Agreement or access to the Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein.
|
||||||
|
b. We may terminate this Agreement if you breach any of the terms or conditions of this Agreement. Upon termination of this Agreement, you must delete and cease use of the Materials. Sections 7 and 9 shall survive the termination of this Agreement.
|
||||||
|
|
||||||
|
9. Governing Law and Jurisdiction.
|
||||||
|
a. This Agreement and any dispute arising out of or relating to it will be governed by the laws of China, without regard to conflict of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement.
|
||||||
|
b. The People's Courts in Hangzhou City shall have exclusive jurisdiction over any dispute arising out of this Agreement.
|
||||||
136
README.md
136
README.md
|
|
@ -1,3 +1,137 @@
|
||||||
|
---
|
||||||
|
license: other
|
||||||
|
license_name: qwen
|
||||||
|
license_link: https://huggingface.co/Qwen/Qwen2.5-Math-PRM-7B/blob/main/LICENSE
|
||||||
|
language:
|
||||||
|
- en
|
||||||
|
- zh
|
||||||
|
pipeline_tag: text-classification
|
||||||
|
library_name: transformers
|
||||||
|
tags:
|
||||||
|
- reward model
|
||||||
|
base_model:
|
||||||
|
- Qwen/Qwen2.5-Math-7B-Instruct
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
# Qwen2.5-Math-PRM-7B
|
# Qwen2.5-Math-PRM-7B
|
||||||
|
|
||||||
Qwen2.5-Math-PRM-7B
|
## Introduction
|
||||||
|
|
||||||
|
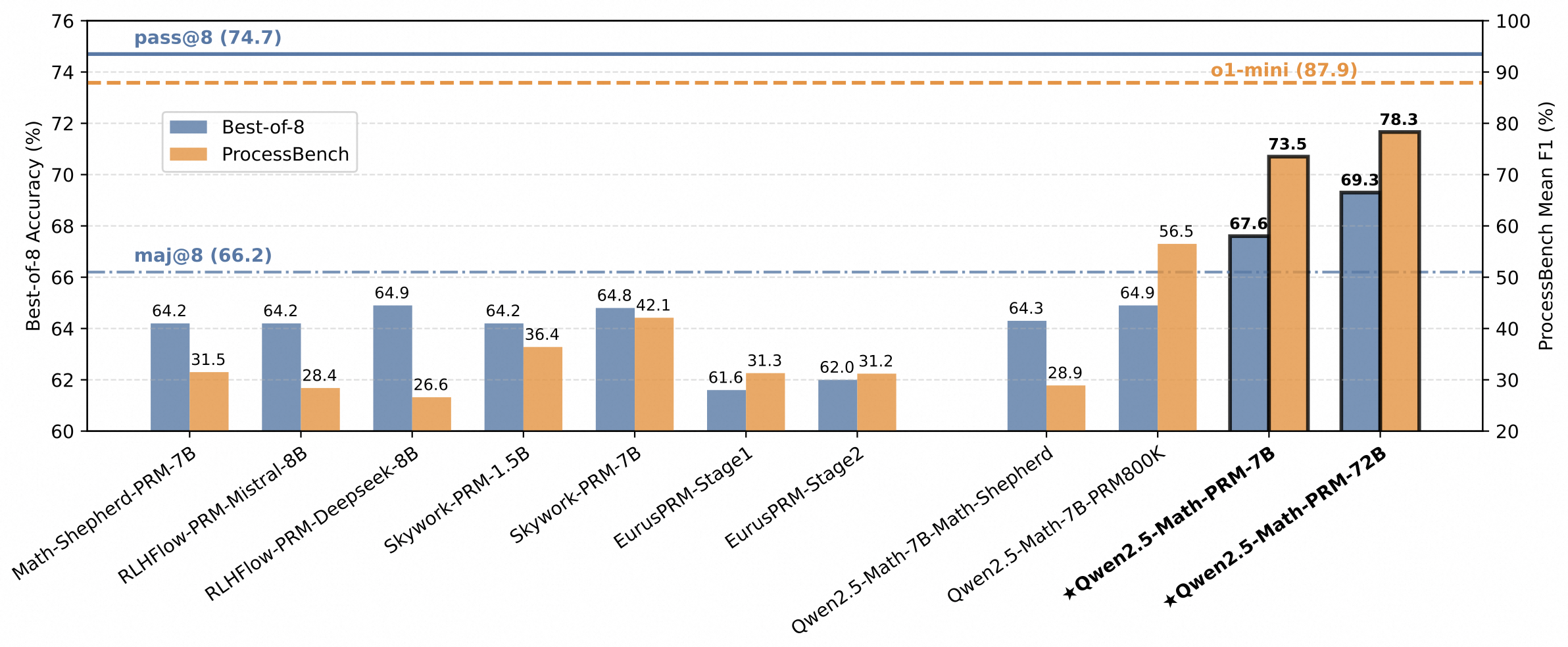
In addition to the mathematical Outcome Reward Model (ORM) Qwen2.5-Math-RM-72B, we release the Process Reward Model (PRM), namely Qwen2.5-Math-PRM-7B and Qwen2.5-Math-PRM-72B. PRMs emerge as a promising approach for process supervision in mathematical reasoning of Large Language Models (LLMs), aiming to identify and mitigate intermediate errors in the reasoning processes. Our trained PRMs exhibit both impressive performance in the Best-of-N (BoN) evaluation and stronger error identification performance in [ProcessBench](https://huggingface.co/papers/2412.06559).
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
## Model Details
|
||||||
|
|
||||||
|
For more details, please refer to our [paper](https://arxiv.org/pdf/2501.07301).
|
||||||
|
|
||||||
|
|
||||||
|
## Requirements
|
||||||
|
* `transformers>=4.40.0` for Qwen2.5-Math models. The latest version is recommended.
|
||||||
|
|
||||||
|
> [!Warning]
|
||||||
|
> <div align="center">
|
||||||
|
> <b>
|
||||||
|
> 🚨 This is a must because `transformers` integrated Qwen2.5 codes since `4.37.0`.
|
||||||
|
> </b>
|
||||||
|
> </div>
|
||||||
|
|
||||||
|
For requirements on GPU memory and the respective throughput, see similar results of Qwen2 [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
|
||||||
|
|
||||||
|
## Quick Start
|
||||||
|
|
||||||
|
> [!Important]
|
||||||
|
>
|
||||||
|
> **Qwen2.5-Math-PRM-7B** is a process reward model typically used for offering feedback on the quality of reasoning and intermediate steps rather than generation.
|
||||||
|
|
||||||
|
### Prerequisites
|
||||||
|
- Step Separation: We recommend using double line breaks ("\n\n") to separate individual steps within the solution if using responses from Qwen2.5-Math-Instruct.
|
||||||
|
- Reward Computation: After each step, we insert a special token "`<extra_0>`". For reward calculation, we extract the probability score of this token being classified as positive, resulting in a reward value between 0 and 1.
|
||||||
|
|
||||||
|
### 🤗 Hugging Face Transformers
|
||||||
|
|
||||||
|
Here we show a code snippet to show you how to use the Qwen2.5-Math-PRM-7B with `transformers`:
|
||||||
|
|
||||||
|
```python
|
||||||
|
import torch
|
||||||
|
from transformers import AutoModel, AutoTokenizer
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
|
||||||
|
def make_step_rewards(logits, token_masks):
|
||||||
|
probabilities = F.softmax(logits, dim=-1)
|
||||||
|
probabilities = probabilities * token_masks.unsqueeze(-1) # bs, seq_len, num_labels
|
||||||
|
|
||||||
|
all_scores_res = []
|
||||||
|
for i in range(probabilities.size(0)):
|
||||||
|
sample = probabilities[i] # seq_len, num_labels
|
||||||
|
positive_probs = sample[sample != 0].view(-1, 2)[:, 1] # valid_tokens, num_labels
|
||||||
|
non_zero_elements_list = positive_probs.cpu().tolist()
|
||||||
|
all_scores_res.append(non_zero_elements_list)
|
||||||
|
return all_scores_res
|
||||||
|
|
||||||
|
|
||||||
|
model_name = "Qwen/Qwen2.5-Math-PRM-7B"
|
||||||
|
device = "auto"
|
||||||
|
|
||||||
|
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
|
||||||
|
model = AutoModel.from_pretrained(
|
||||||
|
model_name,
|
||||||
|
device_map=device,
|
||||||
|
torch_dtype=torch.bfloat16,
|
||||||
|
trust_remote_code=True,
|
||||||
|
).eval()
|
||||||
|
|
||||||
|
|
||||||
|
data = {
|
||||||
|
"system": "Please reason step by step, and put your final answer within \boxed{}.",
|
||||||
|
"query": "Sue lives in a fun neighborhood. One weekend, the neighbors decided to play a prank on Sue. On Friday morning, the neighbors placed 18 pink plastic flamingos out on Sue's front yard. On Saturday morning, the neighbors took back one third of the flamingos, painted them white, and put these newly painted white flamingos back out on Sue's front yard. Then, on Sunday morning, they added another 18 pink plastic flamingos to the collection. At noon on Sunday, how many more pink plastic flamingos were out than white plastic flamingos?",
|
||||||
|
"response": [
|
||||||
|
"To find out how many more pink plastic flamingos were out than white plastic flamingos at noon on Sunday, we can break down the problem into steps. First, on Friday, the neighbors start with 18 pink plastic flamingos.",
|
||||||
|
"On Saturday, they take back one third of the flamingos. Since there were 18 flamingos, (1/3 \times 18 = 6) flamingos are taken back. So, they have (18 - 6 = 12) flamingos left in their possession. Then, they paint these 6 flamingos white and put them back out on Sue's front yard. Now, Sue has the original 12 pink flamingos plus the 6 new white ones. Thus, by the end of Saturday, Sue has (12 + 6 = 18) pink flamingos and 6 white flamingos.",
|
||||||
|
"On Sunday, the neighbors add another 18 pink plastic flamingos to Sue's front yard. By the end of Sunday morning, Sue has (18 + 18 = 36) pink flamingos and still 6 white flamingos.",
|
||||||
|
"To find the difference, subtract the number of white flamingos from the number of pink flamingos: (36 - 6 = 30). Therefore, at noon on Sunday, there were 30 more pink plastic flamingos out than white plastic flamingos. The answer is (\boxed{30})."
|
||||||
|
]
|
||||||
|
}
|
||||||
|
|
||||||
|
messages = [
|
||||||
|
{"role": "system", "content": data['system']},
|
||||||
|
{"role": "user", "content": data['query']},
|
||||||
|
{"role": "assistant", "content": "<extra_0>".join(data['response']) + "<extra_0>"},
|
||||||
|
]
|
||||||
|
conversation_str = tokenizer.apply_chat_template(
|
||||||
|
messages,
|
||||||
|
tokenize=False,
|
||||||
|
add_generation_prompt=False
|
||||||
|
)
|
||||||
|
|
||||||
|
input_ids = tokenizer.encode(
|
||||||
|
conversation_str,
|
||||||
|
return_tensors="pt",
|
||||||
|
).to(model.device)
|
||||||
|
|
||||||
|
outputs = model(input_ids=input_ids)
|
||||||
|
|
||||||
|
step_sep_id = tokenizer.encode("<extra_0>")[0]
|
||||||
|
token_masks = (input_ids == step_sep_id)
|
||||||
|
step_reward = make_step_rewards(outputs[0], token_masks)
|
||||||
|
print(step_reward) # [[1.0, 0.1904296875, 0.9765625, 1.0]]
|
||||||
|
```
|
||||||
|
|
||||||
|
## Citation
|
||||||
|
|
||||||
|
If you find our work helpful, feel free to give us a citation.
|
||||||
|
|
||||||
|
```
|
||||||
|
@article{prmlessons,
|
||||||
|
title={The Lessons of Developing Process Reward Models in Mathematical Reasoning},
|
||||||
|
author={
|
||||||
|
Zhenru Zhang and Chujie Zheng and Yangzhen Wu and Beichen Zhang and Runji Lin and Bowen Yu and Dayiheng Liu and Jingren Zhou and Junyang Lin
|
||||||
|
},
|
||||||
|
journal={arXiv preprint arXiv:2501.07301},
|
||||||
|
year={2025}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,32 @@
|
||||||
|
{
|
||||||
|
"architectures": [
|
||||||
|
"Qwen2ForProcessRewardModel"
|
||||||
|
],
|
||||||
|
"attention_dropout": 0.0,
|
||||||
|
"auto_map": {
|
||||||
|
"AutoConfig": "configuration_qwen2_rm.Qwen2RMConfig",
|
||||||
|
"AutoModel": "modeling_qwen2_rm.Qwen2ForProcessRewardModel"
|
||||||
|
},
|
||||||
|
"bos_token_id": 151643,
|
||||||
|
"eos_token_id": 151645,
|
||||||
|
"hidden_act": "silu",
|
||||||
|
"hidden_size": 3584,
|
||||||
|
"initializer_range": 0.02,
|
||||||
|
"intermediate_size": 18944,
|
||||||
|
"max_position_embeddings": 4096,
|
||||||
|
"max_window_layers": 28,
|
||||||
|
"model_type": "qwen2",
|
||||||
|
"num_attention_heads": 28,
|
||||||
|
"num_hidden_layers": 28,
|
||||||
|
"num_key_value_heads": 4,
|
||||||
|
"rms_norm_eps": 1e-05,
|
||||||
|
"rope_theta": 10000.0,
|
||||||
|
"sliding_window": 131072,
|
||||||
|
"tie_word_embeddings": false,
|
||||||
|
"torch_dtype": "bfloat16",
|
||||||
|
"transformers_version": "4.37.0",
|
||||||
|
"use_cache": true,
|
||||||
|
"use_mrope": false,
|
||||||
|
"use_sliding_window": false,
|
||||||
|
"vocab_size": 152064
|
||||||
|
}
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
{"framework":"Pytorch","task":"text-generation"}
|
||||||
|
|
@ -0,0 +1,140 @@
|
||||||
|
# coding=utf-8
|
||||||
|
# Copyright 2024 The Qwen team, Alibaba Group and the HuggingFace Inc. team. All rights reserved.
|
||||||
|
#
|
||||||
|
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at
|
||||||
|
#
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
"""Qwen2 model configuration"""
|
||||||
|
|
||||||
|
from transformers.configuration_utils import PretrainedConfig
|
||||||
|
from transformers.utils import logging
|
||||||
|
|
||||||
|
|
||||||
|
logger = logging.get_logger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
class Qwen2RMConfig(PretrainedConfig):
|
||||||
|
r"""
|
||||||
|
This is the configuration class to store the configuration of a [`Qwen2Model`]. It is used to instantiate a
|
||||||
|
Qwen2 model according to the specified arguments, defining the model architecture. Instantiating a configuration
|
||||||
|
with the defaults will yield a similar configuration to that of
|
||||||
|
Qwen2-7B-beta [Qwen/Qwen2-7B-beta](https://huggingface.co/Qwen/Qwen2-7B-beta).
|
||||||
|
|
||||||
|
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
||||||
|
documentation from [`PretrainedConfig`] for more information.
|
||||||
|
|
||||||
|
|
||||||
|
Args:
|
||||||
|
vocab_size (`int`, *optional*, defaults to 151936):
|
||||||
|
Vocabulary size of the Qwen2 model. Defines the number of different tokens that can be represented by the
|
||||||
|
`inputs_ids` passed when calling [`Qwen2Model`]
|
||||||
|
hidden_size (`int`, *optional*, defaults to 4096):
|
||||||
|
Dimension of the hidden representations.
|
||||||
|
intermediate_size (`int`, *optional*, defaults to 22016):
|
||||||
|
Dimension of the MLP representations.
|
||||||
|
num_hidden_layers (`int`, *optional*, defaults to 32):
|
||||||
|
Number of hidden layers in the Transformer encoder.
|
||||||
|
num_attention_heads (`int`, *optional*, defaults to 32):
|
||||||
|
Number of attention heads for each attention layer in the Transformer encoder.
|
||||||
|
num_key_value_heads (`int`, *optional*, defaults to 32):
|
||||||
|
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
||||||
|
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
||||||
|
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
||||||
|
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
||||||
|
by meanpooling all the original heads within that group. For more details checkout [this
|
||||||
|
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
|
||||||
|
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
||||||
|
The non-linear activation function (function or string) in the decoder.
|
||||||
|
max_position_embeddings (`int`, *optional*, defaults to 32768):
|
||||||
|
The maximum sequence length that this model might ever be used with.
|
||||||
|
initializer_range (`float`, *optional*, defaults to 0.02):
|
||||||
|
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
||||||
|
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
||||||
|
The epsilon used by the rms normalization layers.
|
||||||
|
use_cache (`bool`, *optional*, defaults to `True`):
|
||||||
|
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
||||||
|
relevant if `config.is_decoder=True`.
|
||||||
|
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
||||||
|
Whether the model's input and output word embeddings should be tied.
|
||||||
|
rope_theta (`float`, *optional*, defaults to 10000.0):
|
||||||
|
The base period of the RoPE embeddings.
|
||||||
|
use_sliding_window (`bool`, *optional*, defaults to `False`):
|
||||||
|
Whether to use sliding window attention.
|
||||||
|
sliding_window (`int`, *optional*, defaults to 4096):
|
||||||
|
Sliding window attention (SWA) window size. If not specified, will default to `4096`.
|
||||||
|
max_window_layers (`int`, *optional*, defaults to 28):
|
||||||
|
The number of layers that use SWA (Sliding Window Attention). The bottom layers use SWA while the top use full attention.
|
||||||
|
attention_dropout (`float`, *optional*, defaults to 0.0):
|
||||||
|
The dropout ratio for the attention probabilities.
|
||||||
|
|
||||||
|
```python
|
||||||
|
>>> from transformers import Qwen2Model, Qwen2Config
|
||||||
|
|
||||||
|
>>> # Initializing a Qwen2 style configuration
|
||||||
|
>>> configuration = Qwen2Config()
|
||||||
|
|
||||||
|
>>> # Initializing a model from the Qwen2-7B style configuration
|
||||||
|
>>> model = Qwen2Model(configuration)
|
||||||
|
|
||||||
|
>>> # Accessing the model configuration
|
||||||
|
>>> configuration = model.config
|
||||||
|
```"""
|
||||||
|
|
||||||
|
model_type = "qwen2"
|
||||||
|
keys_to_ignore_at_inference = ["past_key_values"]
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self,
|
||||||
|
vocab_size=151936,
|
||||||
|
hidden_size=4096,
|
||||||
|
intermediate_size=22016,
|
||||||
|
num_hidden_layers=32,
|
||||||
|
num_attention_heads=32,
|
||||||
|
num_key_value_heads=32,
|
||||||
|
hidden_act="silu",
|
||||||
|
max_position_embeddings=32768,
|
||||||
|
initializer_range=0.02,
|
||||||
|
rms_norm_eps=1e-6,
|
||||||
|
use_cache=True,
|
||||||
|
tie_word_embeddings=False,
|
||||||
|
rope_theta=10000.0,
|
||||||
|
use_sliding_window=False,
|
||||||
|
sliding_window=4096,
|
||||||
|
max_window_layers=28,
|
||||||
|
attention_dropout=0.0,
|
||||||
|
**kwargs,
|
||||||
|
):
|
||||||
|
self.vocab_size = vocab_size
|
||||||
|
self.max_position_embeddings = max_position_embeddings
|
||||||
|
self.hidden_size = hidden_size
|
||||||
|
self.intermediate_size = intermediate_size
|
||||||
|
self.num_hidden_layers = num_hidden_layers
|
||||||
|
self.num_attention_heads = num_attention_heads
|
||||||
|
self.use_sliding_window = use_sliding_window
|
||||||
|
self.sliding_window = sliding_window if use_sliding_window else None
|
||||||
|
self.max_window_layers = max_window_layers
|
||||||
|
|
||||||
|
# for backward compatibility
|
||||||
|
if num_key_value_heads is None:
|
||||||
|
num_key_value_heads = num_attention_heads
|
||||||
|
|
||||||
|
self.num_key_value_heads = num_key_value_heads
|
||||||
|
self.hidden_act = hidden_act
|
||||||
|
self.initializer_range = initializer_range
|
||||||
|
self.rms_norm_eps = rms_norm_eps
|
||||||
|
self.use_cache = use_cache
|
||||||
|
self.rope_theta = rope_theta
|
||||||
|
self.attention_dropout = attention_dropout
|
||||||
|
|
||||||
|
super().__init__(
|
||||||
|
tie_word_embeddings=tie_word_embeddings,
|
||||||
|
**kwargs,
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,14 @@
|
||||||
|
{
|
||||||
|
"bos_token_id": 151643,
|
||||||
|
"pad_token_id": 151643,
|
||||||
|
"do_sample": true,
|
||||||
|
"eos_token_id": [
|
||||||
|
151645,
|
||||||
|
151643
|
||||||
|
],
|
||||||
|
"repetition_penalty": 1.05,
|
||||||
|
"temperature": 0.7,
|
||||||
|
"top_p": 0.8,
|
||||||
|
"top_k": 20,
|
||||||
|
"transformers_version": "4.37.0"
|
||||||
|
}
|
||||||
File diff suppressed because it is too large
Load Diff
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,350 @@
|
||||||
|
{
|
||||||
|
"metadata": {
|
||||||
|
"total_size": 15256944644
|
||||||
|
},
|
||||||
|
"weight_map": {
|
||||||
|
"lm_head.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.14.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.15.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.15.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.16.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.17.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.18.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.19.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.k_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.q_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.v_proj.bias": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
||||||
|
"model.layers.23.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.23.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.24.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.25.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.26.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.k_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.q_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.v_proj.bias": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.27.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.6.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.6.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.k_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.q_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.v_proj.bias": "model-00002-of-00004.safetensors",
|
||||||
|
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
||||||
|
"model.norm.weight": "model-00004-of-00004.safetensors",
|
||||||
|
"score.0.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"score.0.weight": "model-00001-of-00004.safetensors",
|
||||||
|
"score.2.bias": "model-00001-of-00004.safetensors",
|
||||||
|
"score.2.weight": "model-00001-of-00004.safetensors"
|
||||||
|
}
|
||||||
|
}
|
||||||
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,88 @@
|
||||||
|
{
|
||||||
|
"add_prefix_space": false,
|
||||||
|
"added_tokens_decoder": {
|
||||||
|
"151643": {
|
||||||
|
"content": "<|endoftext|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151644": {
|
||||||
|
"content": "<|im_start|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151645": {
|
||||||
|
"content": "<|im_end|>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151646": {
|
||||||
|
"content": "<R>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151647": {
|
||||||
|
"content": "<S>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151648": {
|
||||||
|
"content": "<X>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151649": {
|
||||||
|
"content": "<mask>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151650": {
|
||||||
|
"content": "<sep>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
},
|
||||||
|
"151651": {
|
||||||
|
"content": "<extra_0>",
|
||||||
|
"lstrip": false,
|
||||||
|
"normalized": false,
|
||||||
|
"rstrip": false,
|
||||||
|
"single_word": false,
|
||||||
|
"special": true
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"additional_special_tokens": ["<|im_start|>", "<|im_end|>", "<R>", "<S>", "<X>", "<mask>", "<sep>", "<extra_0>"],
|
||||||
|
"bos_token": null,
|
||||||
|
"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{% if loop.last %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>'}}{% else %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endif %}{% endfor %}{{ '<|endoftext|>' }}",
|
||||||
|
"clean_up_tokenization_spaces": false,
|
||||||
|
"eos_token": "<|im_end|>",
|
||||||
|
"errors": "replace",
|
||||||
|
"model_max_length": 131072,
|
||||||
|
"pad_token": "<|endoftext|>",
|
||||||
|
"split_special_tokens": false,
|
||||||
|
"tokenizer_class": "Qwen2Tokenizer",
|
||||||
|
"unk_token": null
|
||||||
|
}
|
||||||
File diff suppressed because one or more lines are too long
Loading…
Reference in New Issue