10 KiB
| tasks | widgets | model-type | domain | frameworks | backbone | metrics | license | language | tags | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
Apache License 2.0 |
|
|
GTE多语言通用文本表示模型
文本表示是自然语言处理(NLP)领域的核心问题, 其在很多NLP、信息检索的下游任务中发挥着非常重要的作用。近几年, 随着深度学习的发展,尤其是预训练语言模型的出现极大的推动了文本表示技术的效果, 基于预训练语言模型的文本表示模型在学术研究数据、工业实际应用中都明显优于传统的基于统计模型或者浅层神经网络的文本表示模型。这里, 我们主要关注基于预训练语言模型的文本表示。
文本表示示例, 输入一个句子, 输入一个固定维度的连续向量:
- 输入: 吃完海鲜可以喝牛奶吗?
- 输出: [0.27162,-0.66159,0.33031,0.24121,0.46122,...]
文本的向量表示通常可以用于文本聚类、文本相似度计算、文本向量召回等下游任务中。
GTE多语言通用文本表示模型
gte-multilingual-base模型是GTE(通用文本向量,General Text Embedding) 系列模型中的最新的多语言模型,该模型具有几个关键特性:
- 高性能: 在多语言检索任务和多任务表示模型评估中,相比同规模模型,达到了最先进的(SOTA)结果。
- 高推理效率:采用Encoder-Only架构进行训练,使模型体积更小(300M)。LLM架构的向量模型(例如,gte-qwen2-7b-instruct)不同,该模型在推理时对硬件的要求更低,推理速度提高了10倍
- 长上下文:支持最多8192个token的文本长度
- 多语言能力:支持70多种语言
- 弹性向量维度:支持弹性的向量表示,同时保持下游任务的有效性,显著降低存储成本并提高了检索效率。
- 稀疏向量:除了连续向量表示外,还可以生成稀疏向量表示
模型训练更多细节可以参考论文: mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
如何使用
import torch.nn.functional as F
from modelscope import AutoModel, AutoTokenizer
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
model_name_or_path = 'iic/gte_sentence-embedding_multilingual-base'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True)
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=8192, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
dimension=768 # The output dimension of the output embedding, should be in [128, 768]
embeddings = outputs.last_hidden_state[:, 0][:dimension]
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T)
print(scores.tolist())
# [[0.3016996383666992, 0.7503870129585266, 0.3203084468841553]]
- 使用sentence-transformers进行推理
# Requires sentences-transformers>=3.0.0
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import numpy as np
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
model_name_or_path="Alibaba-NLP/gte-multilingual-base"
model = SentenceTransformer(', trust_remote_code=True)
embeddings = model.encode(input_texts) # embeddings.shape (4, 768)
# normalized embeddings
norms = np.linalg.norm(embeddings, ord=2, axis=1, keepdims=True)
norms[norms == 0] = 1
embeddings = embeddings / norms
# sim scores
scores = (embeddings[:1] @ embeddings[1:].T)
print(scores.tolist())
# [[0.301699697971344, 0.7503870129585266, 0.32030850648880005]]
- 使用自定义GTE-Embedding脚本获取连续向量表示和离散向量表示
gte_embedding.py文件在scripts/gte_embedding.py中
from gte_embedding import GTEEmbeddidng
model_name_or_path = 'gte_sentence-embedding_multilingual-base'
model = GTEEmbeddidng(model_name_or_path)
query = "中国的首都在哪儿"
docs = [
"what is the capital of China?",
"how to implement quick sort in python?",
"北京",
"快排算法介绍"
]
embs = model.encode(docs, return_dense=True,return_sparse=True)
print('dense_embeddings vecs', embs['dense_embeddings'])
print('token_weights', embs['token_weights'])
pairs = [(query, doc) for doc in docs]
dense_scores = model.compute_scores(pairs, dense_weight=1.0, sparse_weight=0.0)
sparse_scores = model.compute_scores(pairs, dense_weight=0.0, sparse_weight=1.0)
hybird_scores = model.compute_scores(pairs, dense_weight=1.0, sparse_weight=0.3)
print('dense_scores', dense_scores)
print('sparse_scores', sparse_scores)
print('hybird_scores', hybird_scores)
#dense_scores [0.85302734375, 0.257568359375, 0.76953125, 0.325439453125]
#sparse_scores [0.0, 0.0, 4.600879669189453, 1.570279598236084]
#hybird_scores [0.85302734375, 0.257568359375, 2.1497951507568356, 0.7965233325958252]
模型效果评估
我们在多个下游任务上验证了GTE多语言表征模型的效果,包括多语言检索、跨语言检索、长文本检索,以及在MTEB多任务文本表征评测
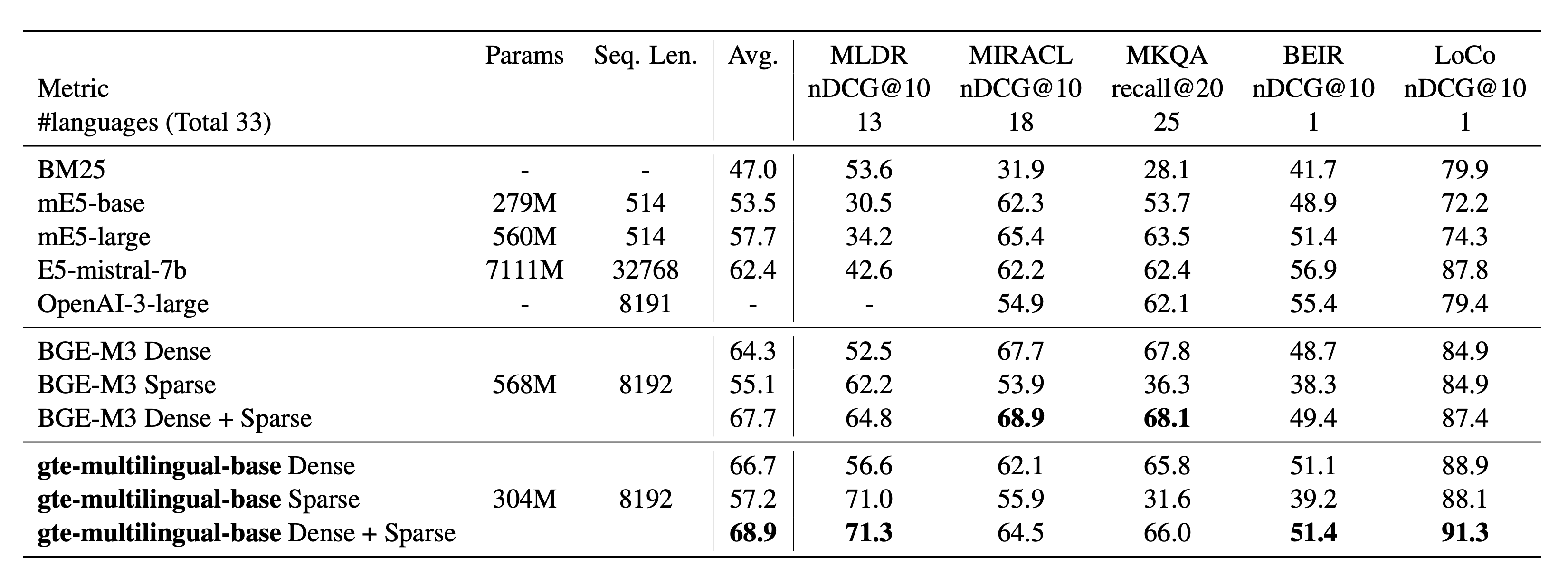
- 检索任务
Retrieval results on MIRACL and MLDR (multilingual), MKQA (crosslingual), BEIR and LoCo (English)
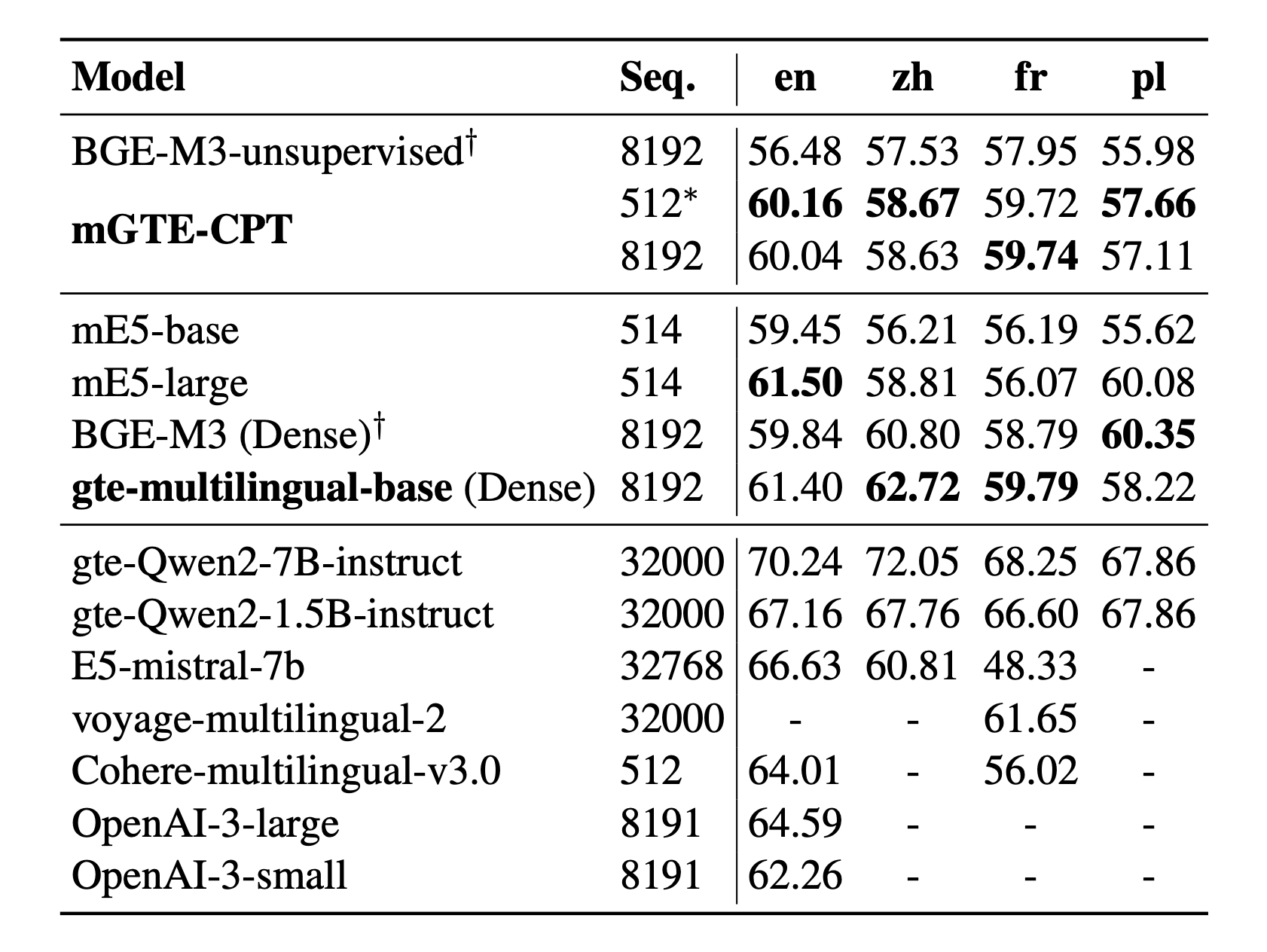
- MTEB多语言
Results on MTEB English, Chinese, French, Polish
更多实验结果可以参考论文paper.
API云服务
除了开源的 GTE 系列模型,GTE系列模型同时在阿里云上提供商用API服务:
- 文本Embedding模型: 提供三种版本的文本嵌入模型:text-embedding-v1/v2/v3,其中v3是最新版本的模型服务
- 文本ReRank模型: 提供gte-rerank模型服务, 模型持续迭代中
Note: API服务背后的模型与开源模型并不完全相同
引用
@article{zhang2024mgte,
title={mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval},
author={Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and others},
journal={arXiv preprint arXiv:2407.19669},
year={2024}
}
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}