|
|
||
|---|---|---|
| .gitattributes | ||
| README.md | ||
| added_tokens.json | ||
| chat_template.json | ||
| config.json | ||
| config_sentence_transformers.json | ||
| cover.png | ||
| custom_st.py | ||
| generation_config.json | ||
| merges.txt | ||
| model.safetensors | ||
| modules.json | ||
| ndcgtop.png | ||
| preprocessor_config.json | ||
| special_tokens_map.json | ||
| tokenizer.json | ||
| tokenizer_config.json | ||
| vocab.json | ||
{kind=link}
{kind=link}
README.md
| license | language | base_model | tags | datasets | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| apache-2.0 |
|
|
|
|
vdr-2b-multi-v1

vdr-2b-multi-v1 is a multilingual embedding model designed for visual document retrieval across multiple languages and domains. It encodes document page screenshots into dense single-vector representations, this will effectively allow to search and query visually rich multilingual documents without the need for any OCR, data extraction pipelines, chunking...
-
Trained on 🇮🇹 Italian, 🇪🇸 Spanish, 🇬🇧 English, 🇫🇷 French and 🇩🇪 German: together they form a new large, open-source, multilingual training dataset of 500k high-quality samples.
-
Cross-lingual Retrieval: substantially better on real-world scenarios. For example, this allows for searching german documents with italian queries.
-
Matryoshka Representation Learning: You can reduce the vectors size 3x and still keep 98% of the embeddings quality.
Usage
The model uses bf16 tensors and allocates ~4.4GB of VRAM when loaded. You can easily run inference and generate embeddings using 768 image patches and a batch size of 16 even on a cheap NVIDIA T4 GPU. This table reports the memory footprint (GB) under conditions of different batch sizes with HuggingFace Transformers and maximum 768 image patches.
| Batch Size | GPU Memory (GB) |
|---|---|
| 4 | 6.9 |
| 8 | 8.8 |
| 16 | 11.5 |
| 32 | 19.7 |
You can generate embeddings with this model in many different ways:
via LlamaIndex
pip install -U llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
model = HuggingFaceEmbedding(
model_name="llamaindex/vdr-2b-multi-v1",
device="cpu", # "mps" for mac, "cuda" for nvidia GPUs
trust_remote_code=True,
)
image_embedding = model.get_image_embedding("image.png")
query_embedding = model.get_query_embedding("some query")
via HuggingFace Transformers
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from PIL import Image
import torch
import math
# more pixels -> better embeddings -> more VRAM -> slower inference
# From my experience, 768 image patches is the right spot for compute efficient embeddings.
max_pixels = 768 * 28 * 28
min_pixels = 1 * 28 * 28
# Load the embedding model and processor
model = Qwen2VLForConditionalGeneration.from_pretrained(
'llamaindex/vdr-2b-multi-v1',
# These are the recommended kwargs for the model, but change them as needed
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="cuda:0"
).eval()
processor = AutoProcessor.from_pretrained(
'llamaindex/vdr-2b-multi-v1',
min_pixels=min_pixels,
max_pixels=max_pixels
)
model.padding_side = "left"
processor.tokenizer.padding_side = "left"
document_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>What is shown in this image?<|im_end|>\n<|endoftext|>"
query_prompt = "<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Query: %s<|im_end|>\n<|endoftext|>"
Encode queries
def encode_queries(queries: list[str], dimension: int) -> torch.Tensor:
"""
Encode a list of queries into a tensor of embeddings.
Args:
queries: A list of strings, each representing a query.
dimension: The desired dimension of the output embeddings.
Returns:
A tensor of shape (num_queries, dimension) containing the encoded queries.
"""
dummy_image = Image.new('RGB', (56, 56))
inputs = processor(
text=[query_prompt % x for x in queries],
images=[dummy_image for _ in queries],
videos=None,
padding='longest',
return_tensors='pt'
).to('cuda:0')
cache_position = torch.arange(0, len(queries))
inputs = model.prepare_inputs_for_generation(
**inputs, cache_position=cache_position, use_cache=False)
with torch.no_grad():
output = self.model(
**inputs,
return_dict=True,
output_hidden_states=True
)
embeddings = output.hidden_states[-1][:, -1]
return torch.nn.functional.normalize(embeddings[:, :dimension], p=2, dim=-1)
Encode documents
def round_by_factor(number: float, factor: int) -> int:
return round(number / factor) * factor
def ceil_by_factor(number: float, factor: int) -> int:
return math.ceil(number / factor) * factor
def floor_by_factor(number: float, factor: int) -> int:
return math.floor(number / factor) * factor
def smart_resize(height: int, width: int) -> tuple[int, int]:
h_bar = max(28, round_by_factor(height, 28))
w_bar = max(28, round_by_factor(width, 28))
if h_bar * w_bar > max_pixels:
beta = math.sqrt((height * width) / max_pixels)
h_bar = floor_by_factor(height / beta, 28)
w_bar = floor_by_factor(width / beta, 28)
elif h_bar * w_bar < min_pixels:
beta = math.sqrt(min_pixels / (height * width))
h_bar = ceil_by_factor(height * beta, 28)
w_bar = ceil_by_factor(width * beta, 28)
return w_bar, h_bar
def resize(image: Image.Image):
new_size = smart_resize(image.height, image.width)
return image.resize(new_size)
def encode_documents(documents: list[Image.Image], dimension: int):
"""
Encode a list of images into a tensor of embeddings.
Args:
documents: A list of PIL Image objects.
dimension: The desired dimension of the output embeddings.
Returns:
A tensor of shape (num_documents, dimension) containing the encoded images.
"""
inputs = processor(
text=[document_prompt] * len(documents),
images=[resize(x) for x in documents],
videos=None,
padding='longest',
return_tensors='pt'
).to('cuda:0')
cache_position = torch.arange(0, len(queries))
inputs = model.prepare_inputs_for_generation(
**inputs, cache_position=cache_position, use_cache=False)
with torch.no_grad():
output = self.model(
**inputs,
return_dict=True,
output_hidden_states=True
)
embeddings = output.hidden_states[-1][:, -1]
return torch.nn.functional.normalize(embeddings[:, :dimension], p=2, dim=-1)
via SentenceTransformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
model_name_or_path="llamaindex/vdr-2b-multi-v1",
device="cuda",
trust_remote_code=True,
# These are the recommended kwargs for the model, but change them as needed if you don't have CUDA
model_kwargs={
"torch_dtype": torch.bfloat16,
"device_map": "cuda:0",
"attn_implementation": "flash_attention_2"
},
)
embeddings = model.encode("image.png")
Training
The model is based on MrLight/dse-qwen2-2b-mrl-v1 and it was trained on the new vdr-multilingual-train dataset that consinsists of 500k high quality, multilingual query image pairs. It was trained for 1 epoch using the DSE approach, with a batch size of 128 and hard-mined negatives.
Results
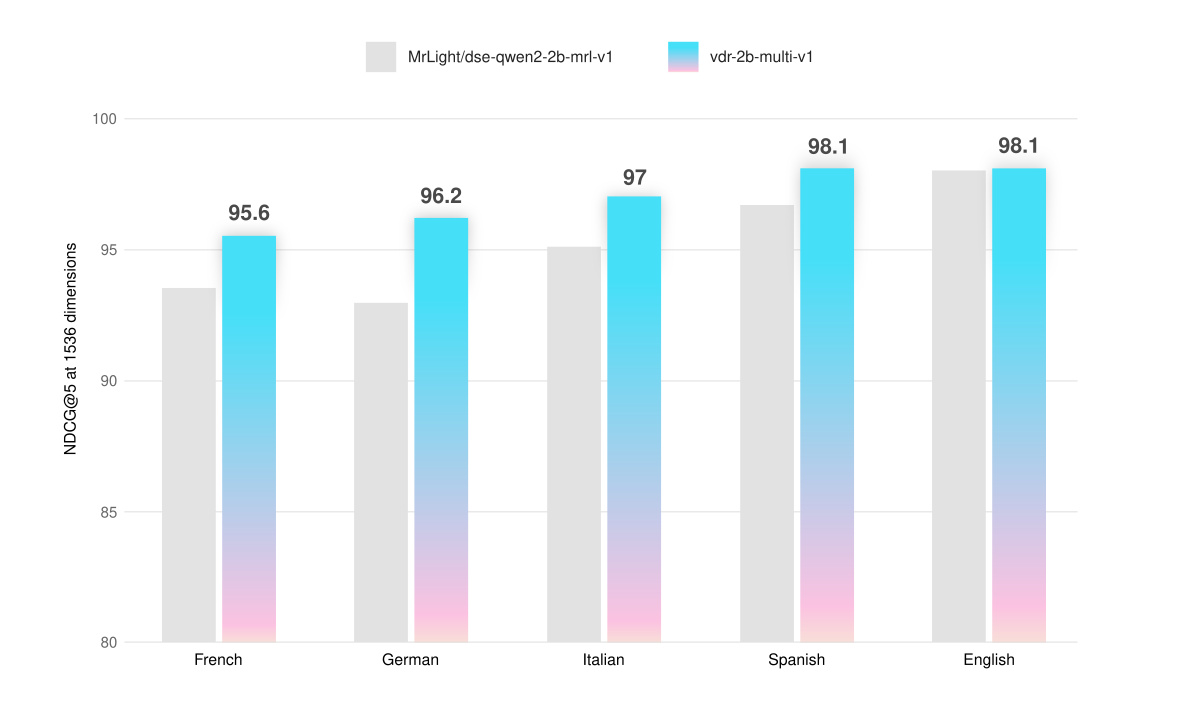
The model has been evaluated on the Vidore benchmark and on custom-built evaluation sets that allow testing its multilingual capabilities on text-only, visual-only and mixed page screenshots. The evaluation dataset is publicly available here on HuggingFace.
All evaluations are performed by calculating NDCG@5 scores using 1536 dimensions vectors and an image resolution that can be represented with maximum 768 tokens.
| Avg | Italian (text) | Italian (visual) | Italian (mix) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 95.1 | 95.1 | 94 | 96.2 |
| vdr-2b-multi-v1 | 97.0 | 96.4 | 96.3 | 98.4 |
| +2% |
| Avg | French (text) | French (visual) | French (mix) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 93.5 | 94.7 | 90.8 | 95.1 |
| vdr-2b-multi-v1 | 95.6 | 95.6 | 93.3 | 97.9 |
| +2.2% |
| Avg | Spanish (text) | Spanish (visual) | Spanish (mix) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 96.7 | 97.2 | 94.7 | 98.2 |
| vdr-2b-multi-v1 | 98.1 | 98.3 | 96.9 | 99.1 |
| +1.4% |
| Avg | German (text) | German (visual) | German (mix) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 93.0 | 93.4 | 90 | 95.5 |
| vdr-2b-multi-v1 | 96.2 | 94.8 | 95.7 | 98.1 |
| +3.4% |
| Avg | English (text) | English (visual) | English (mix) | |
|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 98.0 | 98.3 | 98.5 | 97.1 |
| vdr-2b-multi-v1 | 98.1 | 97.9 | 99.1 | 97.3 |
| +0.1% |
| Avg | shiftproject | government | healthcare | energy | ai | docvqa | arxivqa | tatdqa | infovqa | tabfquad | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| dse-qwen2-2b-mrl-v1 | 83.6 | 79.8 | 95.7 | 96.9 | 92 | 98.2 | 56.3 | 85.2 | 53.9 | 87.5 | 90.3 |
| vdr-2b-multi-v1 | 84.0 | 82.4 | 95.5 | 96.5 | 91.2 | 98.5 | 58.5 | 84.7 | 53.6 | 87.1 | 92.2 |