43 KiB
| frameworks | license | tasks | ||
|---|---|---|---|---|
|
other |
|
端侧可用的 GPT-4o 级视觉、语音、多模态流式大模型
MiniCPM-o 2.6
MiniCPM-o 2.6 是 MiniCPM-o 系列的最新、性能最佳模型。该模型基于 SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和 Qwen2.5-7B 构建,共 8B 参数,通过端到端方式训练和推理。相比 MiniCPM-V 2.6,该模型在性能上有了显著提升,并支持了实时语音对话和多模态流式交互的新功能。MiniCPM-o 2.6 的主要特性包括:
-
🔥 领先的视觉能力。 MiniCPM-o 2.6 在 OpenCompass 榜单上(综合 8 个主流多模态评测基准)平均得分 70.2,以 8B 量级的大小在单图理解方面超越了 GPT-4o-202405、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等主流商用闭源多模态大模型。此外,它的多图和视频理解表现也优于 GPT-4V 和 Claude 3.5 Sonnet,并展现出了优秀的上下文学习能力。
-
🎙 出色的语音能力。 MiniCPM-o 2.6 支持可配置声音的中英双语实时对话。MiniCPM-o 2.6 在语音理解任务(如 ASR 和 STT translation)上的表现优于 GPT-4o-realtime,并在语音对话的语义和声学评估中展现了开源模型中最高的语音生成性能。它还支持情绪/语速/风格控制、语音克隆、角色扮演等进阶能力。
-
🎬 强大的多模态流式交互能力。 作为一项新功能,MiniCPM-o 2.6 能够接受连续的视频和音频流,并和用户进行实时语音交互。在 StreamingBench(针对实时视频理解、全模态(视/音频)理解、多模态上下文理解的综合评测基准)中,MiniCPM-o 2.6 获得开源模型最高分并超过了 GPT-4o-realtime 和 Claude 3.5 Sonnet。
-
💪 强大的 OCR 能力及其他功能。 MiniCPM-o 2.6 进一步优化了 MiniCPM-V 2.6 的众多视觉理解能力,其可以处理任意长宽比的图像,像素数可达 180 万(如 1344x1344)。在 OCRBench 上取得25B 以下最佳水平,超过 GPT-4o-202405 等商用闭源模型。基于最新的 RLHF-V、RLAIF-V 和 VisCPM 技术,其具备了可信的多模态行为,在 MMHal-Bench 上超过了 GPT-4o 和 Claude 3.5,并支持英语、中文、德语、法语、意大利语、韩语等多种语言。
-
🚀 卓越的效率。 除了对个人用户友好的模型大小,MiniCPM-o 2.6 还表现出最先进的视觉 token 密度(即每个视觉 token 编码的像素数量)。它仅需 640 个 token 即可处理 180 万像素图像,比大多数模型少 75%。这一特性优化了模型的推理速度、首 token 延迟、内存占用和功耗。因此,MiniCPM-o 2.6 可以支持 iPad 等终端设备上的高效多模态流式交互。
-
💫 易于使用。 MiniCPM-o 2.6 可以通过多种方式轻松使用:(1) llama.cpp 支持在本地设备上进行高效的 CPU 推理,(2) int4 和 GGUF 格式的量化模型,有 16 种尺寸,(3) vLLM 支持高吞吐量和内存高效的推理,(4) 通过LLaMA-Factory框架针对新领域和任务进行微调,(5) 使用 Gradio 快速设置本地 WebUI 演示,(6) 在线demo。
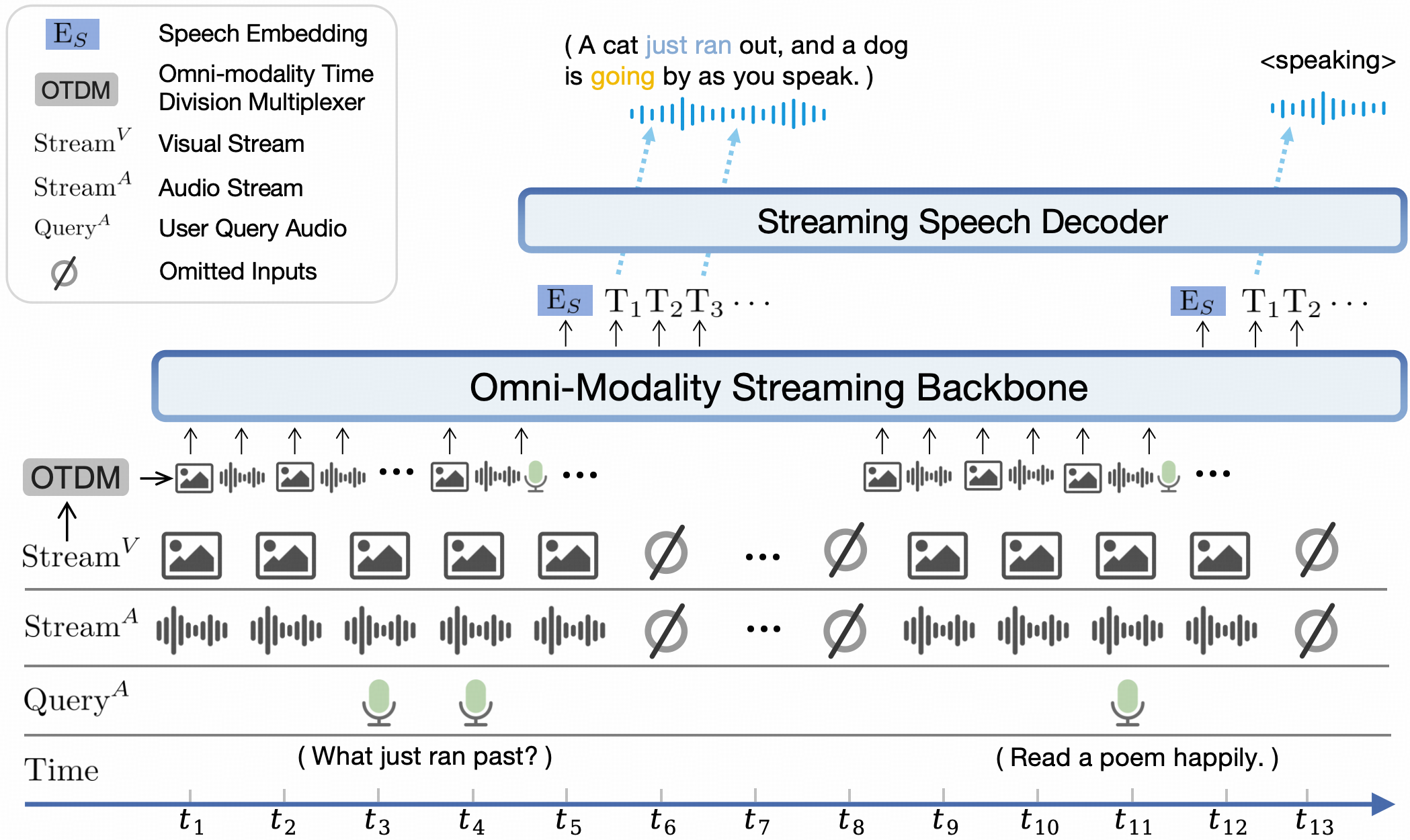
模型架构。
- 端到端全模态架构。 通过端到端的方式连接和训练不同模态的编/解码模块以充分利用丰富的多模态知识。
- 全模态流式机制。 (1) 我们将不同模态的离线编/解码器改造为适用于流式输入/输出的在线模块。 (2) 我们针对大语言模型基座设计了一种时分复用的全模态流式信息处理机制,将平行的不同模态的信息流拆分重组为周期性时间片序列。
- 可配置的声音方案。 我们设计了包含传统文本系统提示词和用于指定模型声音的语音系统提示词结构。从而,模型可在推理时灵活地通过文字或语音样例控制声音风格,支持声音克隆和声音生成等高级能力。
性能评估
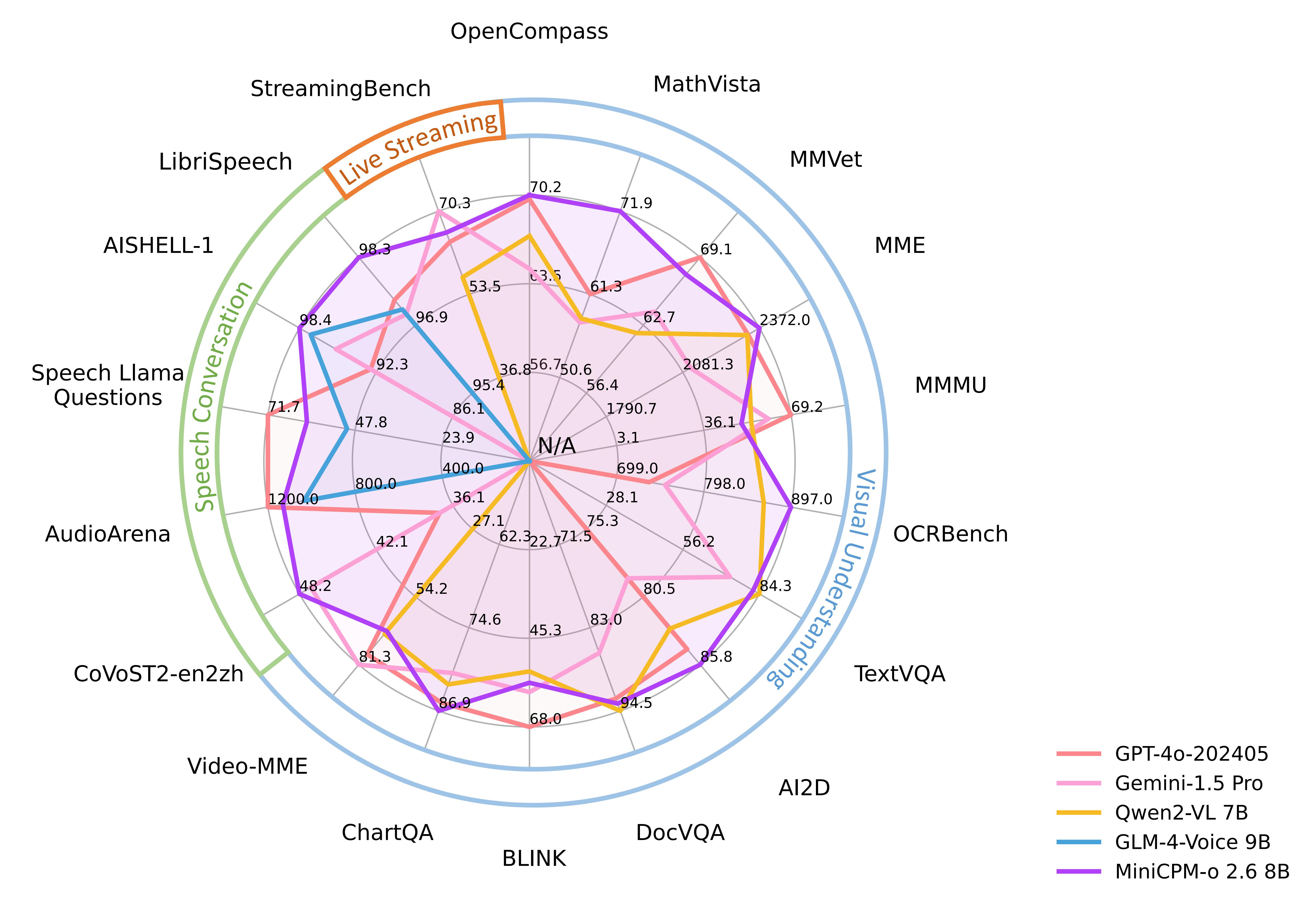
点击查看视觉理解能力详细评测结果。
图像理解能力
| Model | Size | Token Density+ | OpenCompass | OCRBench | MathVista mini | ChartQA | MMVet | MMStar | MME | MMB1.1 test | AI2D | MMMU val | HallusionBench | TextVQA val | DocVQA test | MathVerse mini | MathVision | MMHal Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||||||||||||
| GPT-4o-20240513 | - | 1088 | 69.9 | 736 | 61.3 | 85.7 | 69.1 | 63.9 | 2328.7 | 82.2 | 84.6 | 69.2 | 55.0 | - | 92.8 | 50.2 | 30.4 | 3.6 |
| Claude3.5-Sonnet | - | 750 | 67.9 | 788 | 61.6 | 90.8 | 66.0 | 62.2 | 1920.0 | 78.5 | 80.2 | 65.9 | 49.9 | - | 95.2 | - | - | 3.4 |
| Gemini-1.5-Pro | - | - | 64.4 | 754 | 57.7 | 81.3 | 64.0 | 59.1 | 2110.6 | 73.9 | 79.1 | 60.6 | 45.6 | 73.5 | 86.5 | - | 19.2 | - |
| GPT-4o-mini-20240718 | - | 1088 | 64.1 | 785 | 52.4 | - | 66.9 | 54.8 | 2003.4 | 76.0 | 77.8 | 60.0 | 46.1 | - | - | - | - | 3.3 |
| Open Source | ||||||||||||||||||
| Cambrian-34B | 34B | 1820 | 58.3 | 591 | 50.3 | 75.6 | 53.2 | 54.2 | 2049.9 | 77.8 | 79.5 | 50.4 | 41.6 | 76.7 | 75.5 | - | - | - |
| GLM-4V-9B | 13B | 784 | 59.1 | 776 | 51.1 | - | 58.0 | 54.8 | 2018.8 | 67.9 | 71.2 | 46.9 | 45.0 | - | - | - | - | - |
| Pixtral-12B | 12B | 256 | 61.0 | 685 | 56.9 | 81.8 | 58.5 | 54.5 | - | 72.7 | 79.0 | 51.1 | 47.0 | 75.7 | 90.7 | - | - | - |
| DeepSeek-VL2-27B (4B) | 27B | 672 | 66.4 | 809 | 63.9 | 86.0 | 60.0 | 61.9 | 2253.0 | 81.2 | 83.8 | 54.0 | 45.3 | 84.2 | 93.3 | - | - | 3.0 |
| Qwen2-VL-7B | 8B | 784 | 67.1 | 866 | 58.2 | 83.0 | 62.0 | 60.7 | 2326.0 | 81.8 | 83.0 | 54.1 | 50.6 | 84.3 | 94.5 | 31.9 | 16.3 | 3.2 |
| LLaVA-OneVision-72B | 72B | 182 | 68.1 | 741 | 67.5 | 83.7 | 60.6 | 65.8 | 2261.0 | 85.0 | 85.6 | 56.8 | 49.0 | 80.5 | 91.3 | 39.1 | - | 3.5 |
| InternVL-2.5-8B | 8B | 706 | 68.3 | 822 | 64.4 | 84.8 | 62.8 | 62.8 | 2344.0 | 83.6 | 84.5 | 56.0 | 50.1 | 79.1 | 93.0 | 39.5 | 19.7 | 3.4 |
| MiniCPM-V 2.6 | 8B | 2822 | 65.2 | 852* | 60.6 | 79.4 | 60.0 | 57.5 | 2348.4* | 78.0 | 82.1 | 49.8* | 48.1* | 80.1 | 90.8 | 25.7 | 18.3 | 3.6 |
| MiniCPM-o 2.6 | 8B | 2822 | 70.2 | 897* | 71.9* | 86.9* | 67.5 | 64.0 | 2372.0* | 80.5 | 85.8 | 50.4* | 51.9 | 82.0 | 93.5 | 41.4* | 23.1* | 3.8 |
注意:闭源模型的 Token Density 由 API 收费方式估算得到。
多图和视频理解能力
| Model | Size | BLINK-val | Mantis-Eval | MIRB | Video-MME (wo / w subs) |
|---|---|---|---|---|---|
| Proprietary | |||||
| GPT-4o-20240513 | - | 68 | - | - | 71.9/77.2 |
| GPT4V | - | 54.6 | 62.7 | 53.1 | 59.9/63.3 |
| Open-source | |||||
| LLaVA-NeXT-Interleave 14B | 14B | 52.6 | 66.4 | 30.2 | - |
| LLaVA-One-Vision-72B | 72B | 55.4 | 77.6 | - | 66.2/69.5 |
| MANTIS 8B | 8B | 49.1 | 59.5 | 34.8 | - |
| Qwen2-VL-7B | 8B | 53.2 | 69.6* | 67.6* | 63.3/69.0 |
| InternVL-2.5-8B | 8B | 54.8 | 67.7 | 52.5 | 64.2/66.9 |
| MiniCPM-V 2.6 | 8B | 53 | 69.1 | 53.8 | 60.9/63.6 |
| MiniCPM-o 2.6 | 8B | 56.7 | 71.9 | 58.6 | 63.9/67.9 |
点击查看语音理解和生成能力的详细评测结果。
语音理解能力
| Task | Size | ASR (zh) | ASR (en) | ASR | Emotion | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | CER↓ | WER↓ | BLEU↑ | ACC↑ | ||||||
| Dataset | AISHELL-1 | Fleurs zh | WenetSpeech test-net | LibriSpeech test-clean | GigaSpeech | TED-LIUM | CoVoST en2zh | CoVoST zh2en | MELD emotion | |
| Proprietary | ||||||||||
| GPT-4o-Realtime | - | 7.3* | 5.4* | 28.9* | 2.6* | 12.9* | 4.8* | 37.1* | 15.7* | 33.2* |
| Gemini-1.5-Pro | - | 4.5* | 5.9* | 14.3* | 2.9* | 10.6* | 3.0* | 47.3* | 22.6* | 48.4* |
| Open-Source | ||||||||||
| Qwen2-Audio | 8B | - | 7.5 | - | 1.6 | - | - | 45.2 | 24.4 | 55.3 |
| Qwen2-Audio-Instruction | 8B | 2.6* | 6.9* | 10.3* | 3.1* | 9.7* | 5.9* | 39.5* | 22.9* | 17.4* |
| GLM-4-Voice-Base | 9B | 2.5 | - | - | 2.8 | - | - | - | - | |
| MiniCPM-o 2.6 | 8B | 1.6 | 4.4 | 6.9 | 1.7 | 8.7 | 3.0 | 48.2 | 27.2 | 52.4 |
语音生成能力。
| Task | Size | SpeechQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | ACC↑ | G-Eval (10 point)↑ | Semantic ELO score↑ | Acoustic ELO score↑ | Overall ELO score↑ | UTMOS↑ | ASR-WER↓ | |||
| Dataset | Speech Llama Q. | Speech Web Q. | Speech Trivia QA | Speech AlpacaEval | AudioArena | |||||
| Proprietary | ||||||||||
| GPT-4o-Realtime | 71.7 | 51.6 | 69.7 | 7.4 | 1157 | 1203 | 1200 | 4.2 | 2.3 | |
| Open-Source | ||||||||||
| GLM-4-Voice | 9B | 50.0 | 32.0 | 36.4 | 5.1 | 999 | 1147 | 1035 | 4.1 | 11.7 |
| Llama-Omni | 8B | 45.3 | 22.9 | 10.7 | 3.9 | 960 | 878 | 897 | 3.2 | 24.3 |
| Moshi | 7B | 43.7 | 23.8 | 16.7 | 2.4 | 871 | 808 | 875 | 2.8 | 8.2 |
| Mini-Omni | 1B | 22.0 | 12.8 | 6.9 | 2.5 | 926 | 803 | 865 | 3.4 | 10.0 |
| MiniCPM-o 2.6 | 8B | 61.0 | 40.0 | 40.2 | 5.1 | 1088 | 1163 | 1131 | 4.2 | 9.8 |
声音克隆能力。
| Task | TTS | |
|---|---|---|
| Metric | SIMO↑ | SIMO↑ |
| Dataset | Seed-TTS test-zh | Seed-TTS test-en |
| F5-TTS | 76 | 67 |
| CosyVoice | 75 | 64 |
| FireRedTTS | 63 | 46 |
| MiniCPM-o 2.6 | 57 | 47 |
点击查看多模态流式交互能力评测详细结果。
多模态流式交互能力: StreamingBench 分数
| Model | Size | Real-Time Video Understanding | Omni-Source Understanding | Contextual Understanding | Overall | |||
|---|---|---|---|---|---|---|---|---|
| Proprietary | ||||||||
| Gemini 1.5 Pro | - | 77.4 | 67.8 | 51.1 | 70.3 | |||
| GPT-4o | - | 74.5 | 51.0 | 48.0 | 64.1 | |||
| Claude-3.5-Sonnet | - | 74.0 | 41.4 | 37.8 | 59.7 | |||
| Open-source | ||||||||
| VILA-1.5 | 8B | 61.5 | 37.5 | 26.7 | 49.5 | |||
| LongVA | 7B | 63.1 | 35.9 | 30.2 | 50.7 | |||
| LLaVA-Next-Video-34B | 34B | 69.8 | 41.7 | 34.3 | 56.7 | |||
| Qwen2-VL-7B | 8B | 71.2 | 40.7 | 33.1 | 57.0 | |||
| InternVL2-8B | 8B | 70.1 | 42.7 | 34.1 | 57.0 | |||
| VITA-1.5 | 8B | 70.9 | 40.8 | 35.8 | 57.4 | |||
| LLaVA-OneVision-7B | 8B | 74.3 | 40.8 | 31.0 | 58.4 | |||
| InternLM-XC2.5-OL-7B | 8B | 75.4 | 46.2 | 33.6 | 60.8 | |||
| MiniCPM-V 2.6 | 8B | 72.4 | 40.2 | 33.4 | 57.7 | |||
| MiniCPM-o 2.6 | 8B | 79.9 | 53.4 | 38.5 | 66.0 | |||
典型示例
以下示例为 MiniCPM-o 2.6 部署在 iPad Pro 上所录制得到。



Usage
Inference using Huggingface transformers on NVIDIA GPUs. Requirements tested on python 3.10:
Pillow==10.1.0
torch==2.2.0
torchaudio==2.2.0
torchvision==0.17.0
transformers==4.44.2
librosa==0.9.0
soundfile==0.12.1
vector-quantize-pytorch==1.18.5
vocos==0.1.0
decord
moviepy
Model initialization
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
# load omni model default, the default init_vision/init_audio/init_tts is True
# if load vision-only model, please set init_audio=False and init_tts=False
# if load audio-only model, please set init_vision=False
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-o-2_6',
trust_remote_code=True,
attn_implementation='sdpa', # sdpa or flash_attention_2
torch_dtype=torch.bfloat16,
init_vision=True,
init_audio=True,
init_tts=True
)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True)
# In addition to vision-only mode, tts processor and vocos also needs to be initialized
model.init_tts()
model.tts.float()
Omni mode
we provide two inference modes: chat and streaming
chat inference
import math
import numpy as np
from PIL import Image
from moviepy.editor import VideoFileClip
import tempfile
import librosa
import soundfile as sf
def get_video_chunk_content(video_path, flatten=True):
video = VideoFileClip(video_path)
print('video_duration:', video.duration)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=True) as temp_audio_file:
temp_audio_file_path = temp_audio_file.name
video.audio.write_audiofile(temp_audio_file_path, codec="pcm_s16le", fps=16000)
audio_np, sr = librosa.load(temp_audio_file_path, sr=16000, mono=True)
num_units = math.ceil(video.duration)
# 1 frame + 1s audio chunk
contents= []
for i in range(num_units):
frame = video.get_frame(i+1)
image = Image.fromarray((frame).astype(np.uint8))
audio = audio_np[sr*i:sr*(i+1)]
if flatten:
contents.extend(["<unit>", image, audio])
else:
contents.append(["<unit>", image, audio])
return contents
video_path="/path/to/video"
sys_msg = model.get_sys_prompt(mode='omni', language='en')
# if use voice clone prompt, please set ref_audio
# ref_audio_path = '/path/to/ref_audio'
# ref_audio, _ = librosa.load(ref_audio_path, sr=16000, mono=True)
# sys_msg = model.get_sys_prompt(ref_audio=ref_audio, mode='omni', language='en')
contents = get_video_chunk_content(video_path)
msg = {"role":"user", "content": contents}
msgs = [sys_msg, msg]
# please set generate_audio=True and output_audio_path to save the tts result
generate_audio = True
output_audio_path = 'output.wav'
res = model.chat(
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
temperature=0.5,
max_new_tokens=4096,
omni_input=True, # please set omni_input=True when omni inference
use_tts_template=True,
generate_audio=generate_audio,
output_audio_path=output_audio_path,
max_slice_nums=1,
use_image_id=False,
return_dict=True
)
print(res)
streaming inference
# a new conversation need reset session first, it will reset the kv-cache
model.reset_session()
contents = get_video_chunk_content(video_path, flatten=False)
session_id = '123'
generate_audio = True
# 1. prefill system prompt
res = model.streaming_prefill(
session_id=session_id,
msgs=[sys_msg],
tokenizer=tokenizer
)
# 2. prefill video/audio chunks
for content in contents:
msgs = [{"role":"user", "content": content}]
res = model.streaming_prefill(
session_id=session_id,
msgs=msgs,
tokenizer=tokenizer
)
# 3. generate
res = model.streaming_generate(
session_id=session_id,
tokenizer=tokenizer,
temperature=0.5,
generate_audio=generate_audio
)
audios = []
text = ""
if generate_audio:
for r in res:
audio_wav = r.audio_wav
sampling_rate = r.sampling_rate
txt = r.text
audios.append(audio_wav)
text += txt
res = np.concatenate(audios)
sf.write("output.wav", res, samplerate=sampling_rate)
print("text:", text)
print("audio saved to output.wav")
else:
for r in res:
text += r['text']
print("text:", text)
Audio-Only mode
Mimick
mimick_prompt = "Please repeat each user's speech, including voice style and speech content."
audio_input, _ = librosa.load('xxx.wav', sr=16000, mono=True)
msgs = [{'role': 'user', 'content': [mimick_prompt,audio_input]}]
res = model.chat(
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
max_new_tokens=128,
use_tts_template=True,
temperature=0.3,
generate_audio=True,
output_audio_path='output.wav', # save the tts result to output_audio_path
)
General Speech Conversation with Configurable Voices
Click to view the Python code for enabling MiniCPM-o 2.6 to interact with you in a specified voice.
ref_audio, _ = librosa.load('./assert/voice_01.wav', sr=16000, mono=True) # load the reference audio
# Audio RolePlay: # With this mode, model will role-play the character based on the audio prompt.
sys_prompt = model.get_sys_prompt(ref_audio=ref_audio, mode='audio_roleplay', language='en')
user_question = {'role': 'user', 'content': [librosa.load('xxx.wav', sr=16000, mono=True)[0]]}
# Audio Assistant: # With this mode, model will speak with the voice in ref_audio as a AI assistant.
# sys_prompt = model.get_sys_prompt(ref_audio=ref_audio, mode='audio_assistant', language='en')
# user_question = {'role': 'user', 'content': [librosa.load('xxx.wav', sr=16000, mono=True)[0]]} # Try to ask something!
msgs = [sys_prompt, user_question]
res = model.chat(
image=None,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
max_new_tokens=128,
stream=False,
stream_input=True,
use_tts_template=True,
generate_audio=True,
temperature=0.3,
output_audio_path='result.wav',
)
# round two
history = msgs.append({'role': 'assistant', 'content': res})
user_question = {'role': 'user', 'content': [librosa.load('xxx.wav', sr=16000, mono=True)[0]]}
msgs = history.append(user_question)
res = model.chat(
image=None,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
max_new_tokens=128,
stream=False,
stream_input=True,
use_tts_template=True,
generate_audio=True,
temperature=0.3,
output_audio_path='result_round_2.wav',
)
print(res)
Addressing various audio tasks
Click to show Python code running MiniCPM-o 2.6 with specific audioQA task.
'''
Audio Understanding Task Prompt:
Speech:
ASR with ZH(same as AST en2zh): 请仔细听这段音频片段,并将其内容逐字记录。
ASR with EN(same as AST zh2en): Please listen to the audio snippet carefully and transcribe the content.
Speaker Analysis: Based on the speaker's content, speculate on their gender, condition, age range, and health status.
General Audio:
Audio Caption: Summarize the main content of the audio.
Sound Scene Tagging: Utilize one keyword to convey the audio's content or the associated scene.
'''
task_prompt = "\n"
audio_input, _ = librosa.load('xxx.wav', sr=16000, mono=True)
msgs = [{'role': 'user', 'content': [task_prompt,audio_input]}]
res = model.chat(
image=None,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
max_new_tokens=128,
stream=False,
stream_input=True,
use_tts_template=True,
generate_audio=True,
temperature=0.3,
output_audio_path='result.wav',
)
print(res)
'''
Speech Generation Task Prompt:
Human Instruction-to-Speech: see https://voxinstruct.github.io/VoxInstruct/
Example:
# 在新闻中,一个年轻男性兴致勃勃地说:“祝福亲爱的祖国母亲美丽富强!”他用低音调和低音量,慢慢地说出了这句话。
# Delighting in a surprised tone, an adult male with low pitch and low volume comments:"One even gave my little dog a biscuit" This dialogue takes place at a leisurely pace, delivering a sense of excitement and surprise in the context.
Voice Cloning or Voice Creation: With this mode, model will act like a TTS model.
'''
# Human Instruction-to-Speech:
task_prompt = '' #Try to make some Human Instruction-to-Speech prompt
msgs = [{'role': 'user', 'content': [task_prompt]}] # you can try to use the same audio question
# Voice Cloning mode: With this mode, model will act like a TTS model.
# sys_prompt = model.get_sys_prompt(ref_audio=ref_audio, mode='voice_cloning', language='en')
# text_prompt = f"Please read the text below."
# user_question = {'role': 'user', 'content': [text_prompt, "content that you want to read"]} # using same voice in sys_prompt to read the text. (Voice Cloning)
# user_question = {'role': 'user', 'content': [text_prompt, librosa.load('xxx.wav', sr=16000, mono=True)[0]]} # using same voice in sys_prompt to read 'xxx.wav'. (Voice Creation)
msgs = [sys_prompt, user_question]
res = model.chat(
image=None,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True,
max_new_tokens=128,
stream=False,
stream_input=True,
use_tts_template=True,
generate_audio=True,
temperature=0.3,
output_audio_path='result.wav',
)
Vision-Only mode
MiniCPM-o-2_6 has the same inference methods as MiniCPM-V-2_6
chat with single image
# test.py
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': [image, question]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(res)
## if you want to use streaming, please make sure sampling=True and stream=True
## the model.chat will return a generator
res = model.chat(
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')
Chat with multiple images
Click to show Python code running MiniCPM-o 2.6 with multiple images input.
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
In-context few-shot learning
Click to view Python code running MiniCPM-o 2.6 with few-shot input.
question = "production date"
image1 = Image.open('example1.jpg').convert('RGB')
answer1 = "2023.08.04"
image2 = Image.open('example2.jpg').convert('RGB')
answer2 = "2007.04.24"
image_test = Image.open('test.jpg').convert('RGB')
msgs = [
{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},
{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},
{'role': 'user', 'content': [image_test, question]}
]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
Chat with video
Click to view Python code running MiniCPM-o 2.6 with video input.
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path ="video_test.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params={}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)
Please look at GitHub for more detail about usage.
llama.cpp推理
敬请期待
Int4 量化版
int4 量化版,更低的显存占用(7GB): MiniCPM-o-2_6-int4.
License
Model License
- The code in this repo is released under the Apache-2.0 License.
- The usage of MiniCPM-o and MiniCPM-V series model weights must strictly follow MiniCPM Model License.md.
- The models and weights of MiniCPM are completely free for academic research. after filling out a "questionnaire" for registration, are also available for free commercial use.
Statement
- As an LMM, MiniCPM-o 2.6 generates contents by learning a large mount of multimodal corpora, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-o 2.6 does not represent the views and positions of the model developers
- We will not be liable for any problems arising from the use of the MinCPM-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
Other Multimodal Projects from Our Team
VisCPM | RLHF-V | LLaVA-UHD | RLAIF-V
Citation
If you find our work helpful, please consider citing our papers 📝 and liking this project ❤️!
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={arXiv preprint arXiv:2408.01800},
year={2024}
}